In dataloader.io, before actually importing the data you must first create an Import task. In fact, when creating the task you can save and run it, meaning that this doesn't add extra steps. The beauty of this way is that the next time you want to import the same kind of data, the task is already created, and it just takes one click to enable it. You can also schedule these tasks to run automatically and forget all about them. If you want to build a new task that is similar to one you've already created, you can easily use an old task as a template and build from there, saving you several steps.
So let's get to it...
Creating an Import Task
- Click New Task on the top menu bar.
- Select Import.
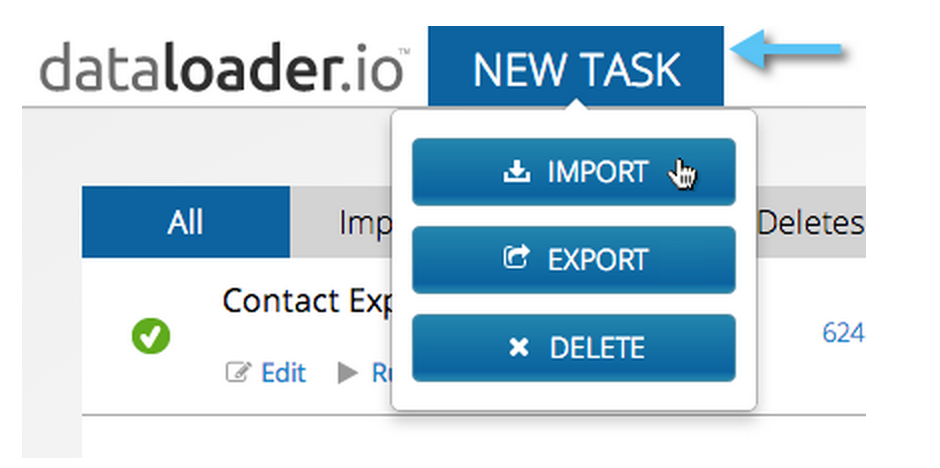
Follow these steps to create your first Import Task:
Step 1: Select your Connection, Operation, and Object
- Select your connection from the drop down menu. Your login credentials are for your default connection. If you wish to use a different Salesforce connection than the one you’re using, create a new connection using the + icon next to the connection drop down.
- Select your operation type: Insert, Upsert, or Update.
- Select the object you wish to import data into - such as Account, Contact, Lead, etc.
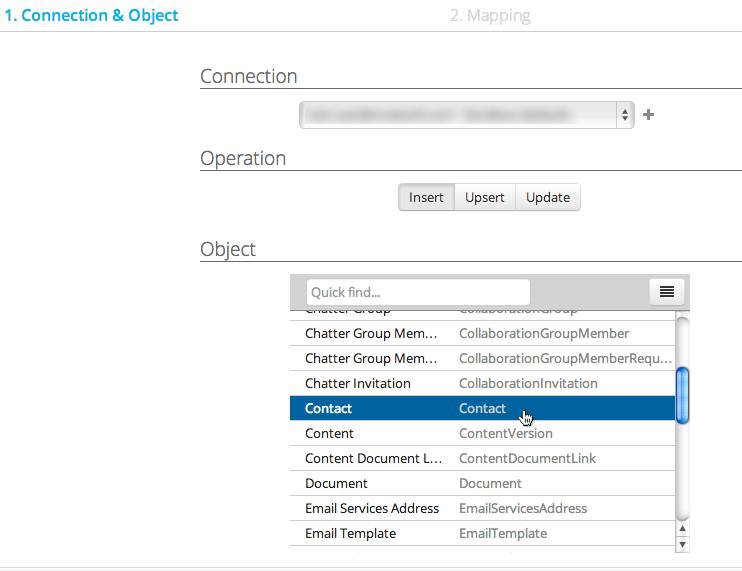
You can use the Quick find function to search through your objects and the Menu button to quickly filter your Standard or Custom objects and show or hide your object names.
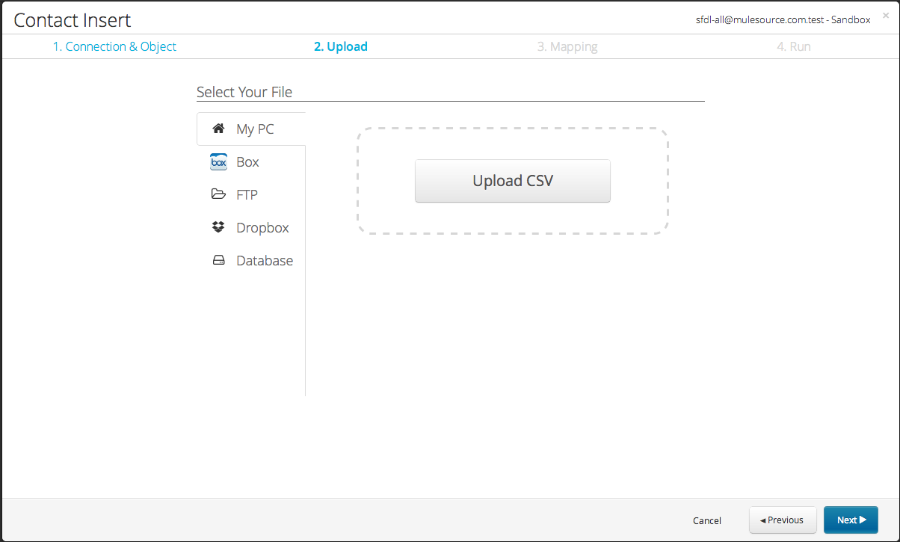
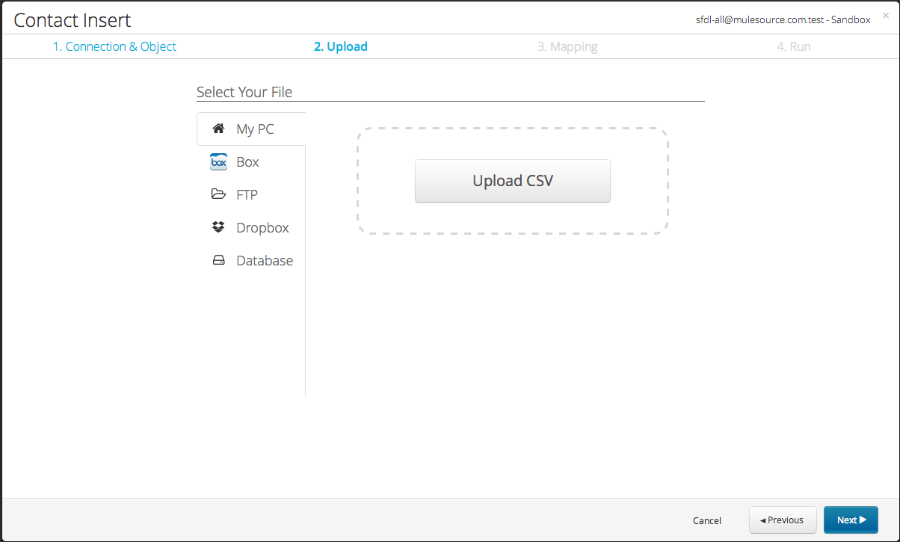
Step 2: Upload your file
You can import your file from your local directory or select it from a cloud repository.
Learn more about how to upload from Box, from Dropbox, from FTP and SFTP
Upload the .CSV file you wish to import by clicking the Upload CSV button, or drag and drop your file inside the dotted rectangle:
Step 3: Map your fields
You can now map your CSV columns to your Salesforce fields. Any matching headers from your input file and your Salesforce object fields map automatically.

Navigate through your mapping
- Use the Quick find on the top left to search through your source fields and find that elusive column from your file.
- Use the quick filters on the top right to see all, mapped, or unmapped fields from Salesforce and quickly find if you are missing some important attributes.
Navigate through your fields
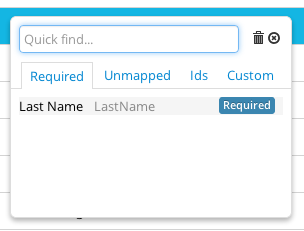
When clicking Salesforce fields, use the Quick find function to search and use the quick filter tabs to find your Required, Unmapped, IDs, and Custom fields.
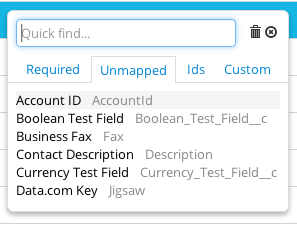
If you want to delete a mapping, just click the trash can next to the mapped Salesforce field.
Mapping source fields into multiple destination fields
You can also map any source field into as many destination fields as you like. It's as simple as just using the Copy icon next to the source field name. If you need to remove a copy, just use the trash can the same way. In the following example we are using the First Name twice, once as the source field for a Lookup and also mapping it into the Contact's First Name.
Do everything faster using keyboard shortcuts
These are the keyboard shortcuts you can use inside the mapping screen:
- Up/Down - Selects a field mapping to edit.
- Enter - Brings up the mapping editor.
While editing a field:
- Tab - Cycles through: Field search, All, Mapped, Unmapped, field list (see below), Cancel, Previous, Next.
- Up/Down - Move up or down in the field list.
- Right/left - Switch between all, IDs, unmapped.
- Enter - Select the field to be mapped.
- Esc - Close field search dialog (without selecting a field).
Inserting Information
When doing inserts, make sure you have mapped all the required fields, otherwise you can't move forward.
Updating Information
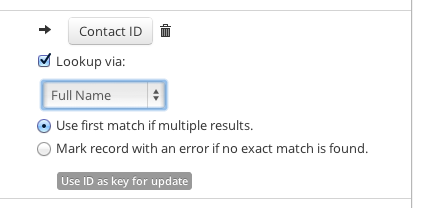
When running updates you must map a column to the Object ID. For example, if you are importing Contacts, note the field called Contact ID which must be mapped to perform the update operation.
What if I don't have that ID from Salesforce?
You have these options:
- Run an Export operation and retrieve those IDs from Salesforce, attach those to your source file, and re-upload the new file.
- Use the lookup functionality to get the IDs based on another field, for example Last Name or an external ID.
Upserting Information (update/insert)
What is an Upsert?
Doing an Upsert means updating the record if it exists, otherwise inserting it.
When performing an upsert you must map a column to an ID field to be used as a key. You can either use Salesforce IDs or external IDs with upsert operations. An external ID field is simply a field which is a unique identifier for your record, other than the Salesforce ID, usually coming from an external system. For example, if you are importing accounts, you may have a field called ERP Account Number which is the identifier for your Accounts inside your ERP system.
Lookup referenced objects
If you need an object ID, but don't have it, you can use the lookup function to retrieve it dynamically. For example, if you're importing Contacts and you have the "Account name", but not the ID, you can use the lookup feature to find it.
Step 4: Save and Run Your Task
On the last step of the wizard is the summary screen with the boiled down information for your task. On this page you can change your task name or choose whether to use the Bulk API or the Batch API (with a certain Batch Size). On the lower part you can also get access to the advanced settings.
Finally, click Save to save your task and run it later or click Save and Run to save your task and run it immediately.
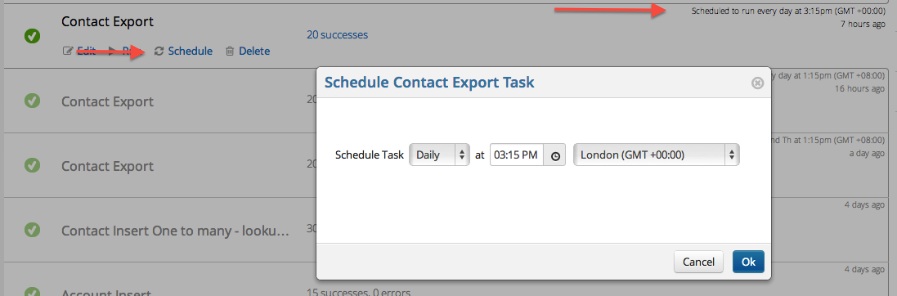
Scheduling
You can Schedule your tasks so that they start running regularly. You can choose between Hourly, Daily, Weekly, or Monthly schedules and switch to different time zones.
After you create your task, you can change the schedule for it by either editing the task and coming back to this screen or directly from the Schedule button below the task on the task list page. There's also a Scheduled tab you can use to quickly find your scheduled tasks:
Using Bulk API
Salesforce Bulk API is based on REST principles and is optimized for loading or deleting large sets of data. Records are processed asynchronously by submitting batches which are processed in the background by Salesforce. Bulk API has some restrictions, for example: related objects exports are not supported by this API. On the other hand, Bulk API processes data in larger batches than Batch API, resulting in a lower API calls usage per operation on large volumes of data.
For more information about Bulk API:
http://www.salesforce.com/us/developer/docs/api_asynch/index.htm
Using Batch API
Whenever the Bulk API checkbox is left unchecked, the Batch API is in use.
Salesforce Batch API is based on SOAP principles and is optimized for real-time client applications that update small numbers of records at a time. Although the SOAP API can also be used for processing large numbers of records, when the data sets contain hundreds of thousands of records, it becomes less practical, in those cases Bulk API is the best option. Batch API processes data in smaller batches than Bulk API, resulting in a higher API calls usage per operation on large volumes of data.
Email Notifications
You can set up your task so that an email notification is sent to you whenever it runs. You can add multiple recipients as well as multiple CCs to the sent email.
When using the free edition of Dataloader.io, you are only allowed to have one task set up to send email notifications. Dataloader.io Professional and Enterprise Editions allows you to implement these in an unlimited amount of tasks.
Advanced Settings
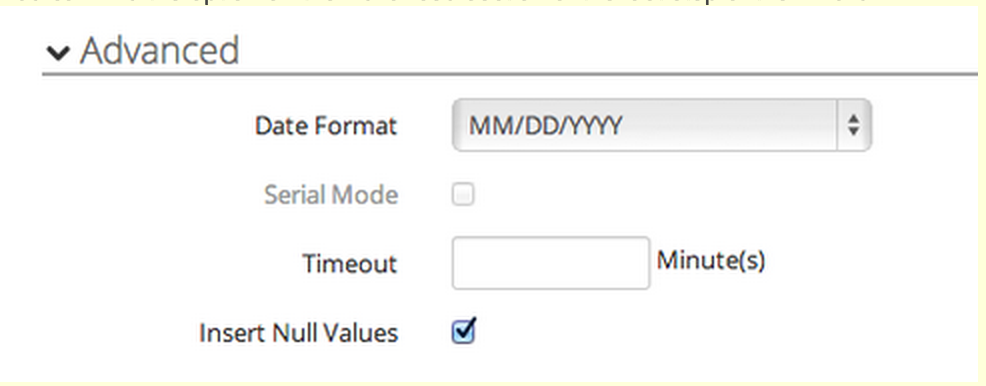
Date Format
Available for both Bulk and Batch APIs. This option allows you to select your import date format, choosing between American (MM/DD/YYYY) and European (DD/MM/YYYY) date formats.
Serial Mode
Available for Bulk API only, this mode guarantees that batches are processed one at a time in Salesforce (avoiding possible database contention). Be careful, this option may significantly increase the processing time for a load.
Timeout
Timeout allows you to set a limit to the maximum time a task can keep running. When the task reaches the timeout threshold it is cancelled automatically. The default timeout set by the system is 2 hours.
Insert Null Values
If this is box is checked, whenever you're updating an existing registry and the new version contains fields with null values, these values overwrite the old values in these fields. If this option is not checked, null values in the update are ignored and the old values for those fields are preserved.
Stronger Security
DataLoader uses one of the strongest server-side encryption mechanisms and provides access to resulting files only to its owners. You can completely remove data from DataLoader's servers by deleting the task from the task menu. In addition, you have full control over where CSV data is stored. Select Save Result Files Externally under advanced settings to guarantee that no CSV files are stored on dataloader.io servers. This feature is only available when using one of the external storages such as Dropbox, Box, (S)FTP, where result files are saved. Note that with this option selected, resulting files won't be available for download from the main page.
Comments
Article is closed for comments.